
GETTING STARTED
Version: 2015-12-09
Recommender101 is a lightweight and easy-to-use framework written in Java to carry out offline experiments for Recommender Systems (RS). It provides the user with various metrics and common evaluation strategies as well as some example recommenders and a dataset. The framework is easily extensible and allows the user to implement own recommenders and metrics.
Implemented algorithms: Nearest neighbors (kNN), SlopeOne, matrix factorization methods, BPR, content-based filtering
Evaluation techniques: Cross-validation; metrics include Precision, Recall, NDCG, MAE, RMSE, AUC, Gini index and others
Download
Table of contents
Downloading Recommender101Running first experiments
Configuring more experiments
Framework structure
Implementing additional metrics
Implementing additional algorithms
Processing data sets
Feedback and contact
Downloading Recommender101
Recommender101 can be downloaded from this site and freely used for non-commercial purposes. After unpacking the downloaded archive, you can start exploring the source code which is provided as an Eclipse project. To import the project into Eclipse click on File->Import->General->Existing Projects into Workspace and select the unpacked folder as the root directory. Be sure to have at least Java 1.7 installed.
Running experiments Back to top
To run the experiments with the recommenders, metrics and dataset defined in the configuration file, execute the main() method of Recommender101.java in the package org.recommender101. To do that in Eclipse, locate the recommender101-core project in the Project Explorer and navigate to src/org.recommender101. Right-click on Recommender101.java and select Run As->Java Application. In the Java console you can see various debug outputs.
Right after starting the experiments, Recommender101 loads and processes the dataset from the data directory and returns its basic statistics, such as the number of users, items and ratings, as well as sparsity, and some averages and frequencies. After that, Recommender101 calculates the defined metrics for the given recommenders and returns the results. As a default, Recommender101 will download the MovieLens100k data set from http://www.grouplens.org/node/73 in the background and run a test experiment, which will take up to a few minutes to complete. Be sure to have an online connection for the first execution of Recommender101, otherwise the demo data set cannot be downloaded. Since the downloaded data set will be stored inside the Recommender101 project, you only need the internet connection for the first run.
Additionally, if you want to try the content-based recommender, there is content for the MovieLens data set available. Please run MovieLens10MDataPreparator beforehand, to unpack and prepare the content information.
Configuring more experiments Back to top
To change the evaluated recommenders, metrics and the dataset as well as some other options used when executing Recommender101.java, open the configuration file recommender101.properties in the conf folder of the project. Here you can find all the relevant parameters together with a documentation on how to set them. By default there are already some typical recommenders and metrics chosen, as well as the dataset MovieLens100k.
As an example, let's examine the default configuration on Recommender101. Some parameters take a string or an integer as a value which is quite straightforward whereas others take the path to a class. Some parameters can have multiple values separated by a comma. If the value of the parameter is the path to a class, you can add additional arguments that are separated from the classpath by a colon. To pass multiple arguments to the classpath, you can use a vertical bar. The following parameters are important for Recommender101 to work and should give an idea on how to configure your experiment. The example values are taken from the default configuration file:
- DataLoaderClass=org.recommender101.data.DefaultDataLoader:filename=data/movielens/ratings.txt is the (class) path to the class that parses your test set (which is likely to be a textual formal) into a DataModel. Additionally there is an argument that specifies the (file system) path to the test set file. If you do not specify the parameter DataModelClass, the standard DataModel will be used by default.
- DataSplitterClass=org.recommender101.data.DefaultDataSplitter:nbFolds=5 is the path to the class that splits your parsed test set for cross validation. The argument is the number of splits. If you do not specify the parameter EvaluationType, cross validation will be used by default.
- AlgorithmClasses=org.recommender101.recommender.extensions.funksvd.FunkSVDRecommender:numFeatures=50|initialSteps=50 are the classes with the recommenders you want to run the experiment on. As you can see in the example the FunkSVDRecommender has two arguments that can be set.
- Metrics=org.recommender101.eval.metrics.Precision:topN=10|targetSet=allrelevantintestset are the classes that implement the metrics you want to measure in the experiment. Again there can be additional arguments like topN and targetSet for Precision.
As you can see in the configuration file you can of course specify multiple recommenders and metrics for one experiment. There are also some global parameters that can be modified:
- GlobalSettings.minRating and GlobalSettings.maxRating sets the scale for the ratings.
- GlobalSettings.listMetricsRelevanceMinRating and GlobalSettings.listMetricsRelevanceMinPercentageAboveAverage define which ratings are considered hits and whether those hits are relative per use or not.
- GlobalSettings.numOfThreads is used for systems with multiple CPUs to enable parallel processing.
Framework structure Back to top
Recommender101 is structured as follows: On the highest level there are four directories. The folder conf contains the main configuration file of Recommender101. In this file all configuration parameters are stored. It is used by default and can be edited to the users needs. However it is also possible to use an external configuration file given as a parameter to Recommender101.java.
The folder data stores binary files that are processed by Recommender101. You should use it to hold your test data. Initially this folder is empty but Recommender101 provides a class to acquire sample data from the MovieLens dataset (MovieLens100k).
The folder lib is used to store external libraries. If your own recommenders and metrics rely on specific libraries, you should store them in this directory.
The folder src contains the implementation of Recommender101. Its package org.recommender101 is structured as follows:
| Package | Description |
|---|---|
| data | Classes and interfaces to load test data |
| data.extensions | Extensions for more complex datasets |
| eval.impl | Central classes of Recommender101 |
| eval.interfaces | Interfaces that metrics need to implement |
| eval.metrics | Basic metrics to evaluate experiments |
| eval.metrics.extensions | Additional metrics |
| recommender | Interfaces that recommenders need to implement |
| recommender.baseline | Example implementations of recommenders |
| recommender.extensions | More complex recommender implementations |
| tools | Helper classes for various things |
| Recommender101.java | Starting class to execute Recommender101 |
The following image shows the basic structure of the most important classes, associations and dependencies (click to enlarge):
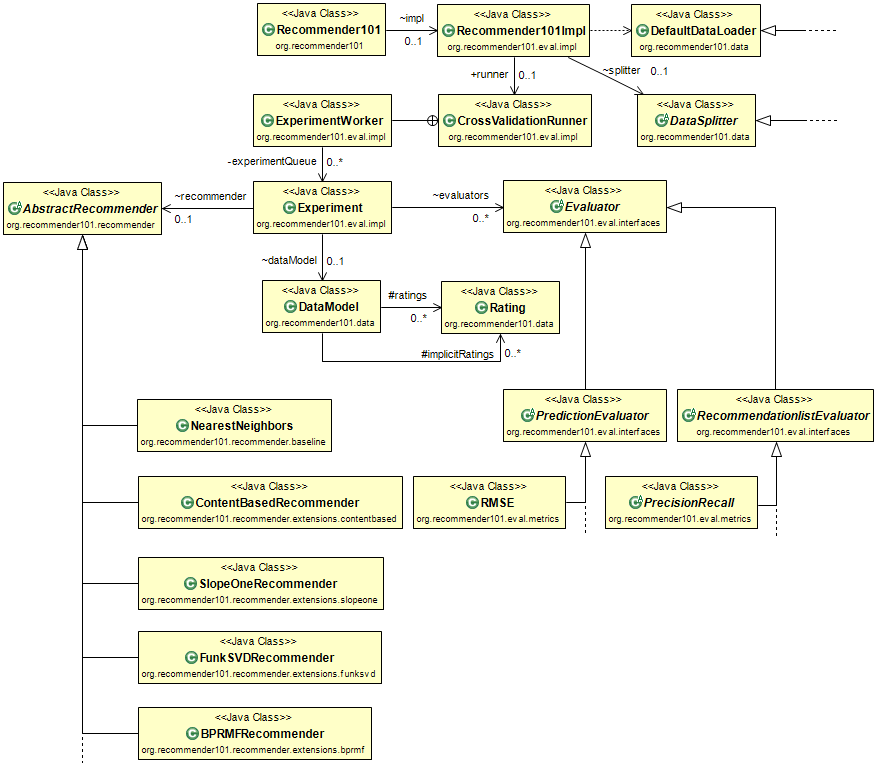
If you take a closer look at Recommender101.java, you can see that the following actions take place when executing it: At first it is checked whether an external configuration file is passed as an argument or not and loaded if applicable. After that the sample data from the MovieLens dataset is downloaded and placed in the data-folder if needed. Then an object of the type Recommender101Impl is instantiated and given the configuration. With its methods runExperiments() and getLastResults() the experiments are calculated and retrieved. Finally the method printSortedEvaluationResults() outputs the results.
As you can see Recommender101Impl is the central class of an experiment in Recommender101. It wraps settings, dataset, metrics and recommenders. You can either call it via executing Recommender101.java or use the helper methods in Recommender101.java to access it from an external program. Metrics and algorithms are bundled in instances of Experiment which can be processed simultaneously by the ExperimentWorker.
Implementing additional algorithms Back to top
The package org.recommender101.recommender contains the implementation of various common recommenders. In baseline you can find baseline recommendation methods as well as more complex recommenders in extensions. All recommenders inherit from the abstract class AbstractRecommender.
To create your own recommender, start by creating a new class in the extensions directory that inherits from AbstractRecommender. As you can see, there are three methods that need to be implemented:
- float predictRating(int user, int item) predicts the rating for a pair of user and item. The parameters are passed as integer values originating from the experiments DataModel. More on this later.
- List<Integer> recommendItems(int user) generates a ranked list of recommendations for a given user.
- void init() is called by the instantiating class after object creation and is used to set up the recommender if there is initialization to be done.
This is the bare minimum that the recommender needs. A good example to look at is the PopularityAndAverage baseline recommender. You also might take a look at the method recommendItemsByRatingPrediction(int user) of the class AbstractRecommender which you might need to overwrite in case your own recommender cannot make rating predictions or you want to include a better heuristic.
Implementing additional metrics Back to top
A metric in Recommender101 is always based on the class Evaluator found in org.recommender101.eval.interfaces. There are two types of metrics currently available in Recommender101: PredictionEvaluator and RecommendationlistEvaluator. Both these classes inherit from Evaluator and every metric should inherit from either of them. PredictionEvaluator metrics measure the quality of rating predictions. Typical examples include the MAE or the RMSE. RecommendationlistEvaluator metrics evaluate the quality of a whole list (e.g., Precision, Recall,...).
For a PredictionEvaluator there are two methods that you need to implement. The first one, addTestPrediction(Rating r, float prediction), is called for every rating and its prediction by the recommender. You should calculate the value of the metric incrementally at these calls and store the value within the metric's class since it is only instanced once per experiment. Finally, to retrieve the metric's value there is the method getPredictionAccuracy(). There is also an initialize() method that you may want to overwrite. Take a look at RMSE.java for an example.
A RecommendationlistEvaluator again needs two methods to be implemented. addRecommendations(Integer user, List<Integer> list) is called for every user and his list of recommended items. As with PredictionEvaluator you calculate and store the value of the metric incrementally within the class. For the output getEvaluationResult() is called and if you need initialization you can overwrite initialize(). A short example can be found in UserCoverage.java with a longer one being Recall.java.
Processing datasets Back to top
A dataset, which is typically a text file, must be processed to be used by Recommender101. The format for data handled by Recommender101 is defined in the classes DataModel and Rating and processed by the classes DataSplitter and DefaultDataLoader found in the package org.recommender101.data. As you can see by looking into DataModel.java, data is managed with a couple of sets and maps. To add additional information to the data, the map extraInformation can be used. Also check out Rating.java to see how ratings are stored within DataModel.
To split a DataModel for cross validation, the DataSplitter should be used. To do that you need to implement the method splitData(DataModel dataModel) which splits the DataModel into a number of sets of ratings. A basic implementation DefaultDataSplitter that works with simple datasets is available in the package.
Finally, to create a DataModel you need to create a DataLoader that parses your dataset into a DataModel. You need to implement the method loadData(DataModel dm) that reads your text file(s) and fills the DataModel. For the MovieLens dataset the basic DefaultDataLoader is available. Take a look at it to see how to fill the DataModel with information.
Feedback Back to top
Feedback of any type is highly appreciated. Please send your comments or questions to the Recommender101 developer team.
ReferenceBack to top
When referring to Recommender101, please use the following bibliography entry:
D. Jannach, L. Lerche, F. Gedikli, G. Bonnin: What recommenders recommend - An analysis of accuracy, popularity, and sales diversity effects, 21st International Conference on User Modeling, Adaptation and Personalization (UMAP 2013), Rome, Italy, 2013.
@INPROCEEDINGS{JannachUMAP2013,
AUTHOR = {D. Jannach and L. Lerche and F. Gedikli and G. Bonnin},
TITLE = {What recommenders recommend - An analysis of accuracy, popularity, and sales diversity effects},
BOOKTITLE = {Proc. 21st International Conference on User Modeling, Adaptation and Personalization (UMAP 2013)},
YEAR = {2013},
address = {Rome, Italy}
}